
Llama Gpt 项目的简单介绍以及切换CUDA的方法
llama-gpt 是一个 需要自己架设,离线,类似ChatGPT的聊天机器人,由Llama 2 提供支持。
官方 github 地址: https://github.com/getumbrel/llama-gpt.git
官方简介:
A self-hosted, offline, ChatGPT-like chatbot. Powered by Llama 2. 100% private, with no data leaving your device.
主要内容
体验
这是笔者第一次体验gpt类的工具, 之前并没有尝试过chatGPT, 感觉这个llama-gpt 勉强可用, 不过更多的还是期待它未来的表现。
- 仓库的版本是 纯CPU 运算的, 所以速度很慢。 笔者的U 是amd 5600, 一个问题需要几分钟才能开始响应, 到响应结束还需要一段时间。 2023年8月21日
- 不过可以自己切换到N卡的 CUDA 上进行运算, 有点麻烦, 但是可以切换。
- 响应的内容 没有排版,这个很难受,并且笔者目前没有找到办法去解决。 后续更新可见: https://github.com/getumbrel/llama-gpt/issues/28
- 可以用中文提问, 但是默认情况下会回复英文
- 会无视一些输入提示词, 比如 想让它省略解释说明部分, 但是没用,它一定会给你解释一下。
下面看几张图。
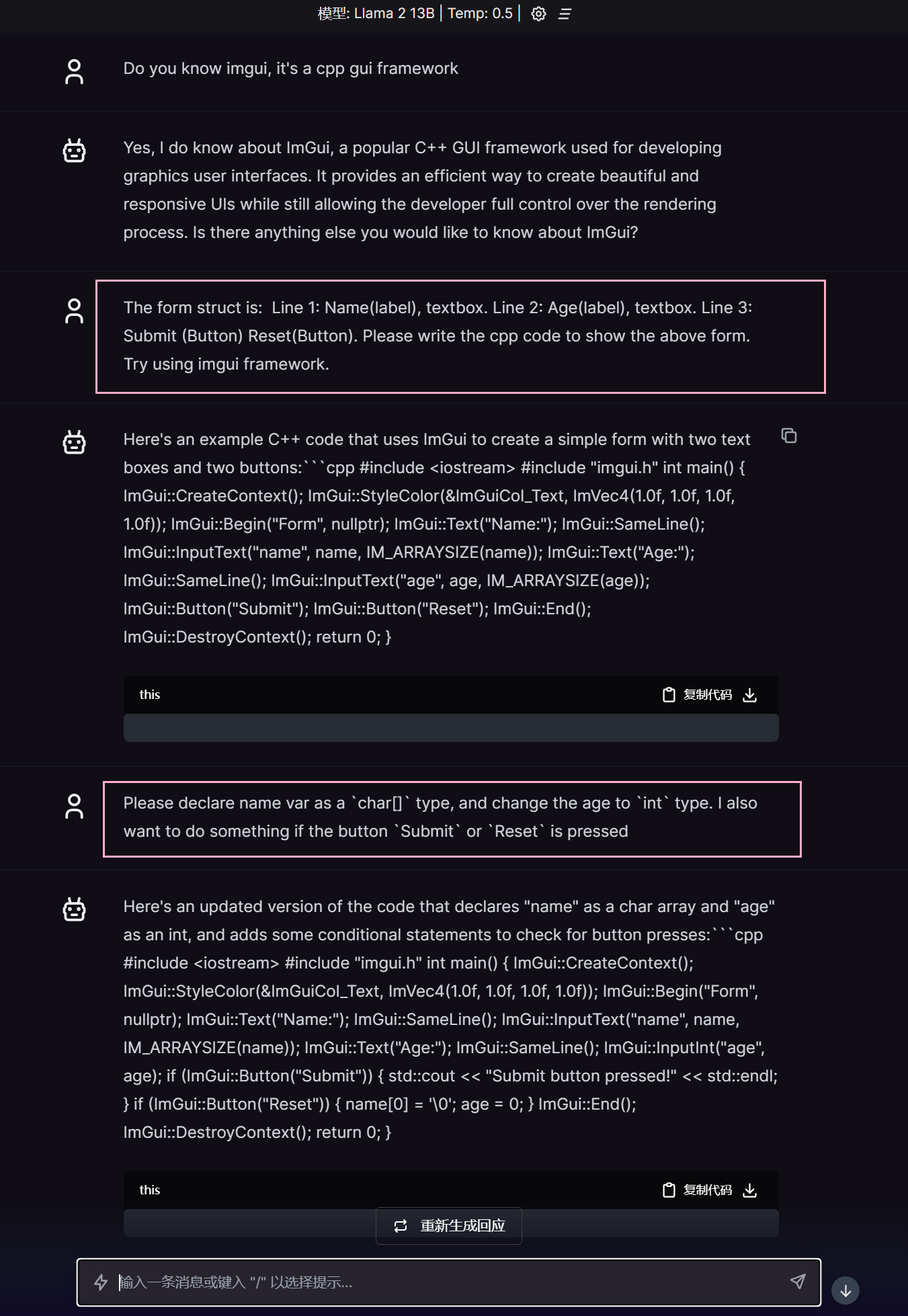
虽然排版很难受, 但是生成出现的东西, 还是可以考虑的。
|
|
使用 https://codebeautify.org/cpp-formatter-beautifier 自动格式化
|
|
第二版代码比第一版本多了一些内容, 但是仍然没帮我声明 name, age 两个变量 😆
偶尔的情况下, 会给一个很好的排版。
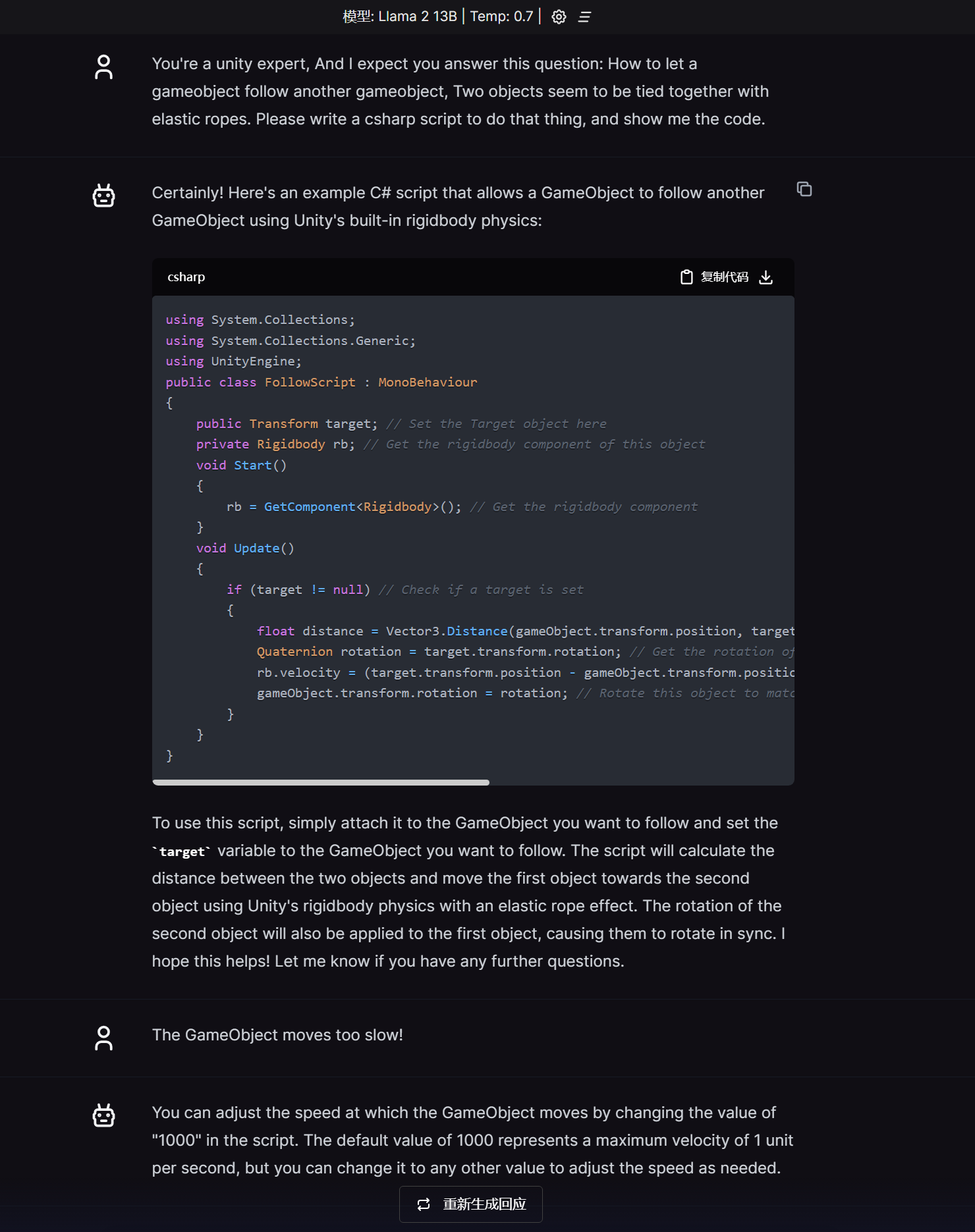
可以生成 unity的脚本, 这里还可以看到是存在上下文语境的。 但是我看了一下日志, 感觉就是把聊天记录都发了一遍过去。。 好像openai 也是这么处理的
应用
- 小段代码生成
- 一些常见的算法代码生成
- 生成的冒泡排序可以使用, 但是 快速排序却有语法问题, 且没给我解决。。
- 中文翻译成英文
- 但是无法从英文翻译中文
- 问一些乱七八糟的
- 生成 CURD 相关的代码。
切换部分内容到GPU上运行
本文描述的方法是使用 N卡的CUDA 进行运算。 更换之后, 大多数问题在几秒内就可以开始回答了。
这只是一个临时的办法, 官方可能会在不久的将来支持 CUDA。 可见 https://github.com/getumbrel/llama-gpt/issues/6
笔者在 Debian 11 上进行了测试, 成功运行了 13B模型。
更多的说明在最后部分
简单版本
- 编译 llama-cpp-python 的 cuda 版本 镜像
- 手动把模型映射到容器中
- 调整并使用
llama-gpt/api/run.sh文件来启动
长版本
- 安装 并且设置好 docker, 包括 nvidia container-toolkit
- git clone https://github.com/abetlen/llama-cpp-python.git
- 准备好 模型
- llama-2-7b-chat.bin - https://huggingface.co/TheBloke/Nous-Hermes-Llama-2-7B-GGML/resolve/main/nous-hermes-llama-2-7b.ggmlv3.q4_0.bin
- llama-2-13b-chat.bin - https://huggingface.co/TheBloke/Nous-Hermes-Llama2-GGML/resolve/main/nous-hermes-llama2-13b.ggmlv3.q4_0.bin
- 我觉得 7b 或者 13b 的就足够了
- 经过尝试, 7b q4 版本 质量较差, 建议使用13B版本。
- 下载好的模型放到宿主机的某个文件夹, 比如:
/home/debian/docker/llama-models - 我使用的是
llama-2-13b-chat.bin这个模型
- 查阅文档: https://github.com/abetlen/llama-cpp-python/tree/main/docker#cuda_simple
- 不需要执行最后的 docker run 命令, 使用
docker build -t cuda_simple .构建好镜像即可 - 修改版本的 Dockerfile: https://github.com/Aincvy/llama-cpp-python/blob/dockerfile-cn-mirrors/docker/cuda_simple/Dockerfile-CN
- 使用了 阿里的 apt 源
- 使用了 清华大学的 python 源
- 不需要执行最后的 docker run 命令, 使用
- 执行命令
sudo docker tag cuda_simple llama-cpp-python-cuda:latest - 寻找一个目录作为 docker compose 的目录, 比如:
/home/debian/docker-compose/llama-gpt-cuda - 新建文件
docker-compose.yaml,并填充下面的内容
|
|
- 创建一个目录:
data - 创建一个文件:
data/run.sh并填充下面的内容 从 llama-gpt/api/run.sh 复制,然后调整的
|
|
- 调整
n_gpu_layers参数, 过大可能会导致 OOM, 我是3060 12G, 37已经非常极限了。 sudo docker compose up查看能否正常运行, 如果没有什么问题的话, 则使用sudo docker compose up -d进入后台运行。
其他说明
- GPU 的占用好像没有跑满, 大约在 30% 附近。 CPU还是100% 在运行,
- 速度确实提升了不少,
但是没有到达立即响应的地步。很多问题可以在几秒内开始回答。 - 聊天记录越多, 越容易 崩溃, 暂时没看到崩溃原因,只看到了 exit code 0
- 可能和docker 容器关闭再启动也有点关系把。
- 应该是 到达了 max_token 或者显存爆了
- 模型的路径好像只能用
/models/llama-2-13b-chat.bin,或者只能是/models/目录, 否则 UI 程序会出现问题。
其他
尝试了一下 https://github.com/oobabooga/text-generation-webui , 同样安装有点麻烦, 但是这个排版很好。 使用的同一个模型
2023年9月12日 今日尝试, 无法加载这个模型了。