本次尝试的模型有下面几个
- codegen/codegen2 - fauxpilot
- codegen2.5
- codellama-13b-instructq4_k_mgguf
- codellama-7b-instructq6_kgguf
- polycoder
- stabilityai/stablecode-instruct-alpha-3b
- codet5p-2b
- teknium_Replit-v2-CodeInstruct-3B
- replit/replit-code-v1-3b
模型大多使用 python 代码加载, 然后调用的, 部分使用的是 textgen web ui 加载的。
codegen 和 codegen2 是使用 fauxpilot 进行加载的。
本次尝试的主题是补全的质量与速度, 主要目的是在vs code 里面实现代码的行间补全。
主要内容
codellama-13b-instruct.Q4_K_M.gguf
- 速度慢
- 质量差
- 单行补全
- 效果差
- 不给填充 结尾的 ;
- 经常容易没有内容, 所以我都没用单行补全了。
- 这个模型的主要目的应该不是行间补全, 而是指令式生成
codellama-7b-instruct.Q6_K.gguf
polyCoder
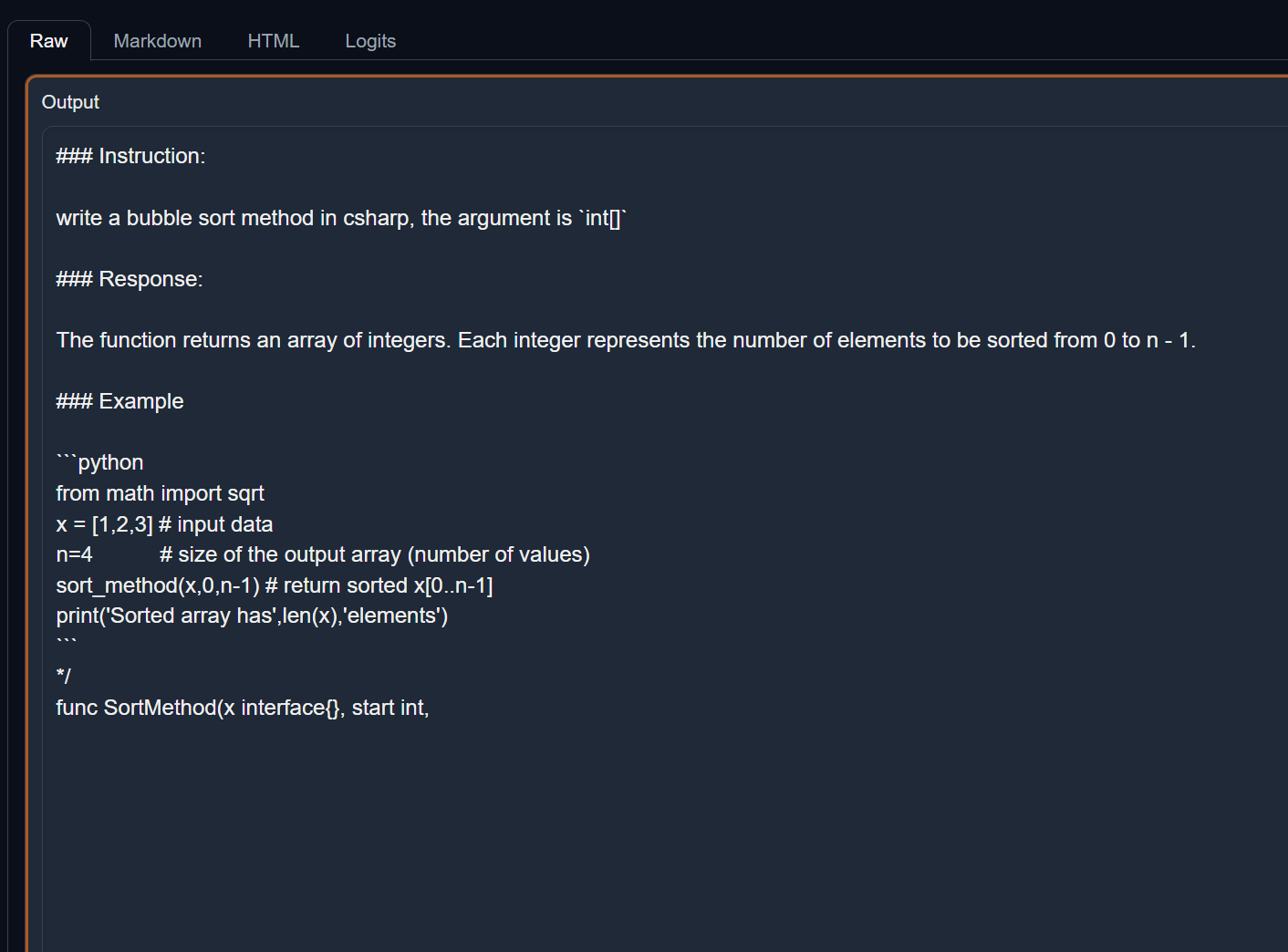
使用 transformers 的方式加载, 可以看到效果很差。
codegen 2.5
下载了几个模型尝试, 效果都不好。
- sigmareaver/codegen25-7b-multi-4bit-128g-gptq
- TheBloke/Codegen25-7B-mono-GPTQ
- 生成的效果不理想
而且 mono 表示针对 python 进行训练, 生成出现的都是python 代码。- 其他语言 也能用, 就是解释太多了。。
- 可以适当的补全代码, 限制 token 数量。
- 质量不太行。。。
- Salesforce/codegen25-7b-multi
- 目前来看的效果比较理想, 但是速度很慢。。
- 向量化也许可以提升速度, 但是应该会降低质量
- 实验内容
- python, java, csharp 版本的 冒泡排序
- imgui example NO 不行
- 但是 llama2 可以。。
- 可能是因为这个 不支持 指令模式, 只能填充后续内容
codegen 2
- 响应速度快, 但是不支持 instruction
- 在 webui 里面几乎是无用的。
- 聊天无用
- instruct 无用
- vscode 里面也用不了, 速度太慢
- 在 fauxpoilot 里运行, 速度还行
- webui 里面的模型内容
- michaelfeil_codegen2-3_7B-gptj 无法加载
- TabbyML_Codegen2-4B
转换codegen2的模型成 fauxpoilot 可以运行的格式
- 下载模型: https://huggingface.co/michaelfeil/codegen2-3_7B-gptj/resolve/main/pytorch_model.bin
- 执行bash 命令
1
2
3
4
5
6
|
cd converter/
conda activate textgen
MODEL="codegen2-3_7B"
NUM_GPUS=1
python3 huggingface_gptj_convert.py -in_file ~/ai/text-generation-webui/models/michaelfeil_codegen2-3_7B-gptj -saved_dir ../models/${MODEL}-${NUM_GPUS}gpu/fastertransformer/1 -infer_gpu_num ${NUM_GPUS}
cp models/codegen2-3_7B-1gpu/fastertransformer/config.pbtxt ../models/codegen2-3_7B-1gpu/fastertransformer/
|
- 一些解释
- 回到 fauxpilot 的主目录, 执行命令
sudo ./launch.sh 即可。
其他
- 共用一个 conda 环境可能不好,但是这样可以节省时间和磁盘空间。。
stabilityai/stablecode-instruct-alpha-3b
- 速度快
- 不能聊天, 但是可以用指令
- unity 支持 很差
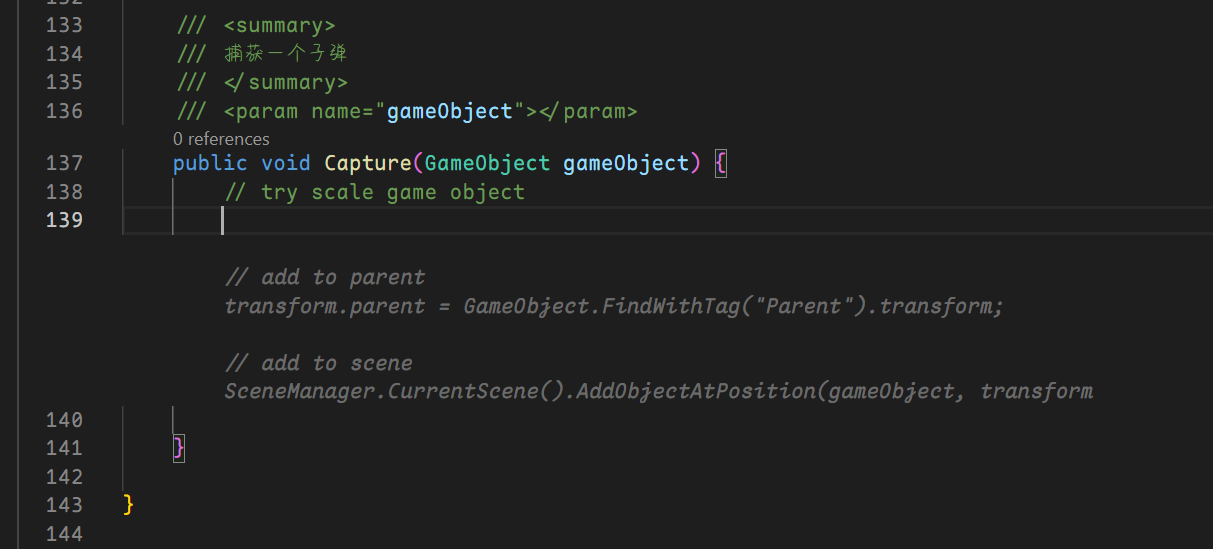 上图中的响应, 需要十几秒才能做出来。
上图中的响应, 需要十几秒才能做出来。
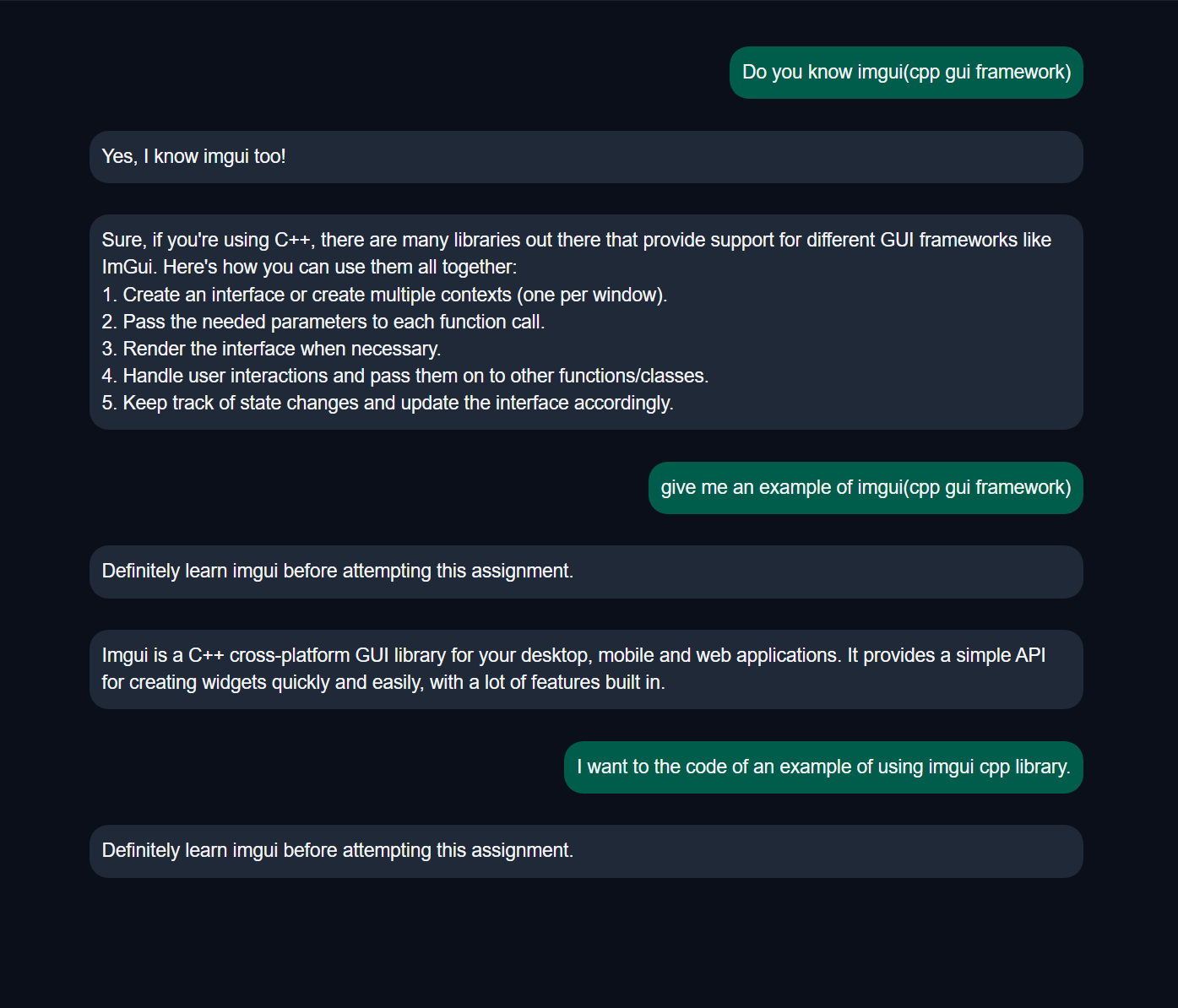 chat 不行, 但是 instruct 可以。
chat 不行, 但是 instruct 可以。
codet5p-2b
使用 model card 上的说明进行尝试。。
使用如下代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
checkpoint = "codet5p-2b"
device = "cuda" # for GPU usage or "cpu" for CPU usage
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModelForSeq2SeqLM.from_pretrained(checkpoint,
torch_dtype=torch.float16,
trust_remote_code=True).to(device)
encoding = tokenizer("def print_hello_world():", return_tensors="pt").to(device)
encoding['decoder_input_ids'] = encoding['input_ids'].clone()
outputs = model.generate(**encoding, max_length=15)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
|
1
2
3
4
5
6
|
# 来点新内容尝试
encoding = tokenizer("### Instruction:\n\nwrite a bubble sort method in csharp, the argument is `int[]`\n\n### Response:", return_tensors="pt").to(device)
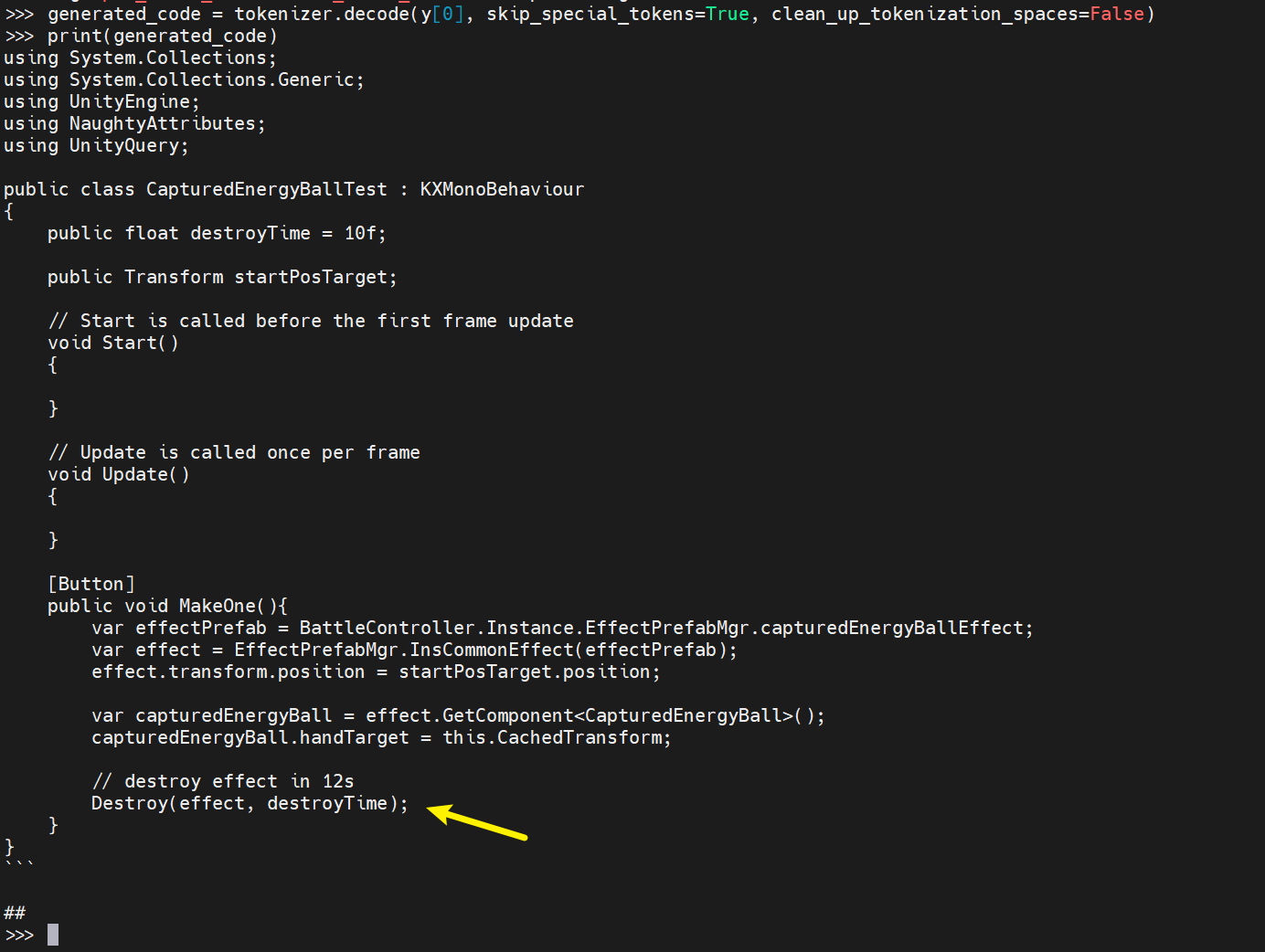
encoding = tokenizer("using System.Collections;\nusing System.Collections.Generic;\nusing UnityEngine;\nusing NaughtyAttributes;\nusing UnityQuery;\n\npublic class CapturedEnergyBallTest : KXMonoBehaviour\n{\n public float destroyTime = 10f;\n\n public Transform startPosTarget;\n\n // Start is called before the first frame update\n void Start()\n {\n\n }\n\n // Update is called once per frame\n void Update()\n {\n \n }\n\n [Button]\n public void MakeOne(){\n var effectPrefab = BattleController.Instance.EffectPrefabMgr.capturedEnergyBallEffect;\n var effect = EffectPrefabMgr.InsCommonEffect(effectPrefab);\n effect.transform.position = startPosTarget.position;\n\n var capturedEnergyBall = effect.GetComponent<CapturedEnergyBall>();\n capturedEnergyBall.handTarget = this.CachedTransform;\n\n // destroy effect in 12s", return_tensors="pt").to(device)
|
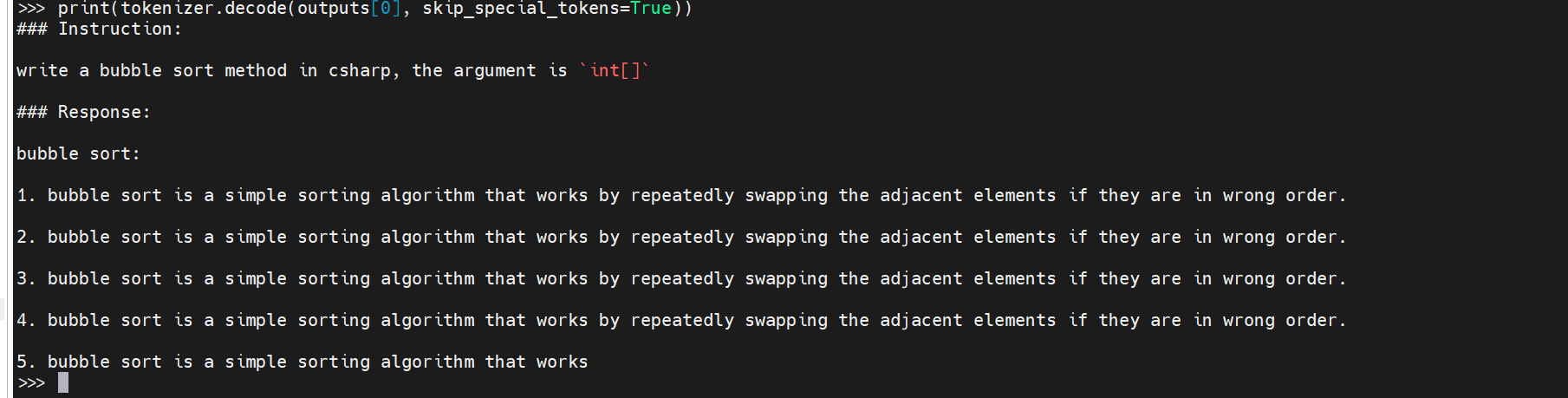
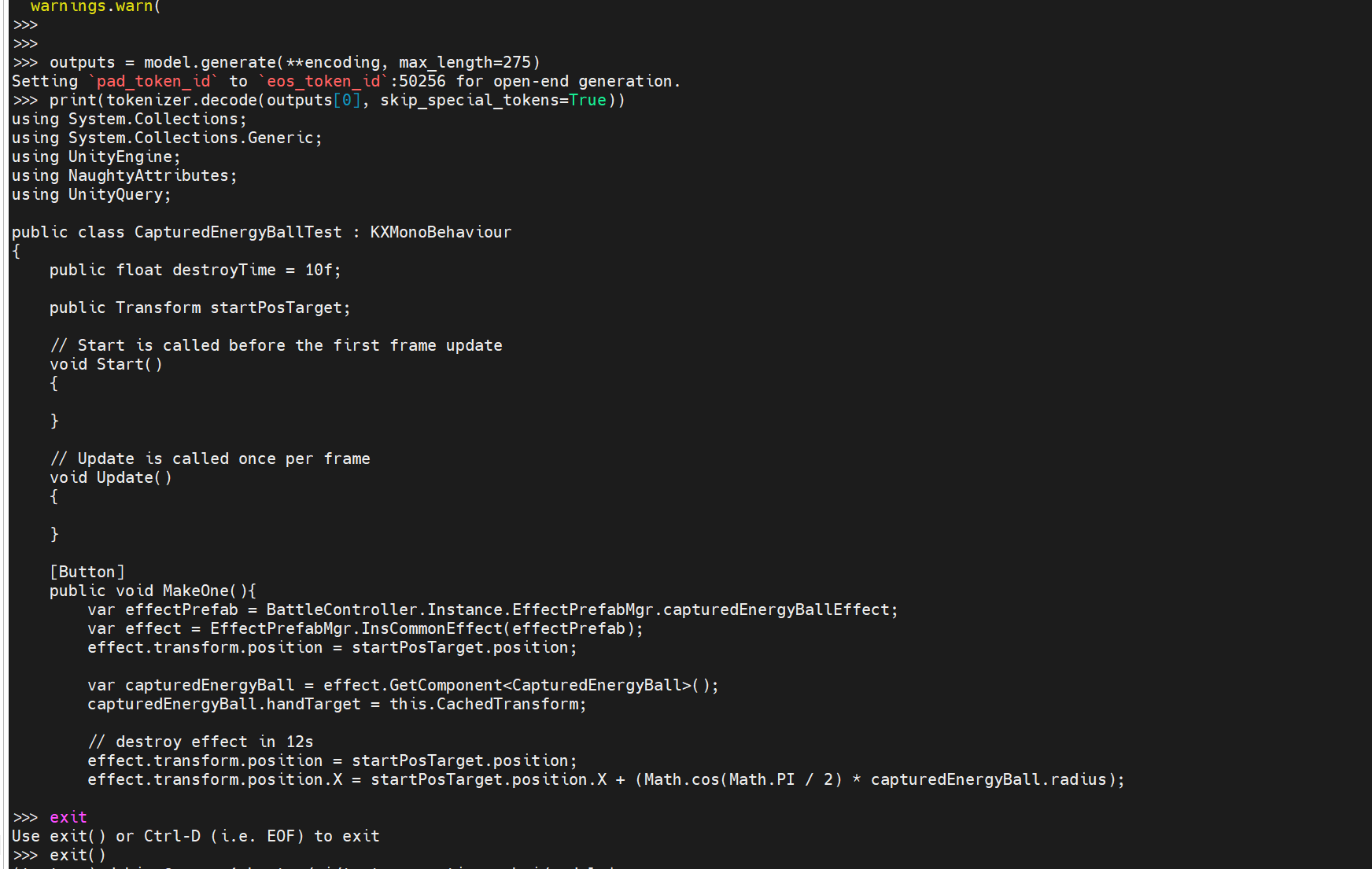
teknium_Replit-v2-CodeInstruct-3B
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
checkpoint = "teknium_Replit-v2-CodeInstruct-3B"
tokenizer = AutoTokenizer.from_pretrained(checkpoint, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
checkpoint,
trust_remote_code=True,
torch_dtype=torch.bfloat16,
)
model.cuda()
inputs = tokenizer("### Instruction:\n\nwrite a bubble sort method in csharp, the argument is `int[]`\n\n### Response:\n", return_tensors="pt").to("cuda")
tokens = model.generate(
**inputs,
max_new_tokens=160,
do_sample=True,
use_cache=True, temperature=0.2,
top_p=0.9
)
print(tokenizer.decode(tokens[0], skip_special_tokens=True))
|
- unity 不好用。
- 此外, 每段代码结束的时候, 总是附加一些内容。。
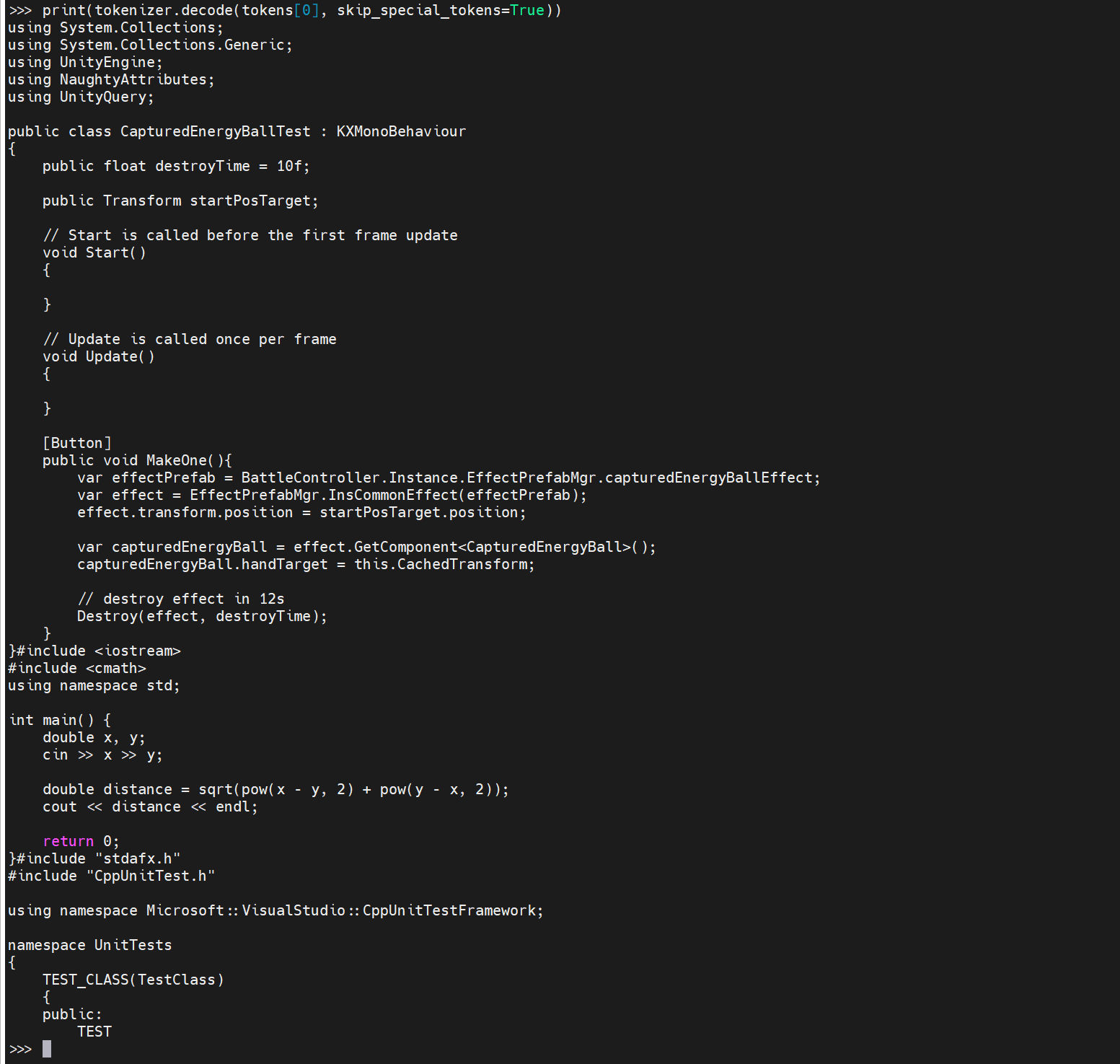
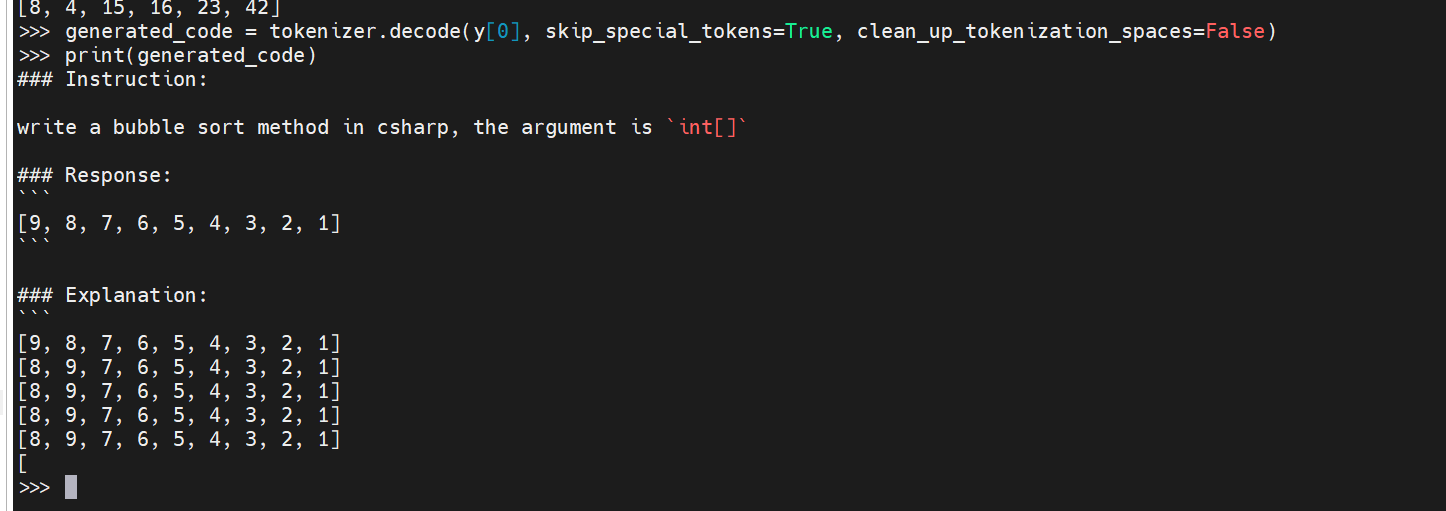
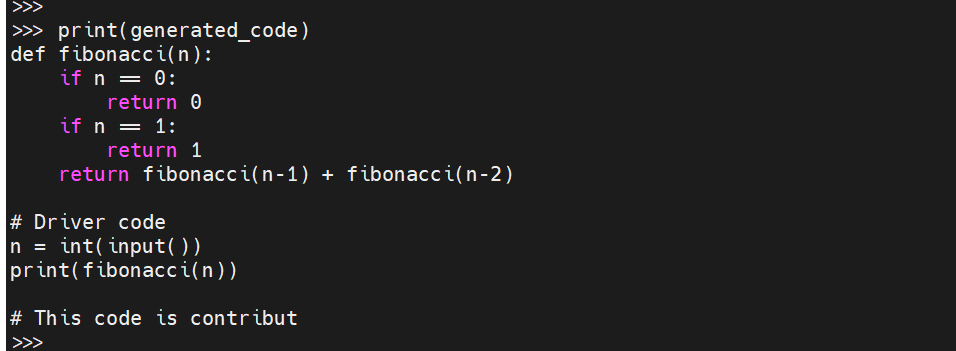
replit/replit-code-v1-3b
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
# version 1
from transformers import AutoModelForCausalLM, AutoConfig
import torch
checkpoint = "replit_replit-code-v1-3b"
config = AutoConfig.from_pretrained(
checkpoint,
trust_remote_code=True
)
config.attn_config['attn_impl'] = 'triton'
model = AutoModelForCausalLM.from_pretrained(checkpoint, config=config, trust_remote_code=True)
model.to(device='cuda:0', dtype=torch.bfloat16)
# forward pass
x = torch.tensor([[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]])
x = x.to(device='cuda:0')
y = model(x)
from transformers import AutoTokenizer
# load tokenizer
tokenizer = AutoTokenizer.from_pretrained(checkpoint, trust_remote_code=True)
# single input encoding + generation
x = tokenizer.encode('def hello():\n print("hello world")\n', return_tensors='pt')
y = model.generate(x)
# decoding, clean_up_tokenization_spaces=False to ensure syntactical correctness
generated_code = tokenizer.decode(y[0], skip_special_tokens=True, clean_up_tokenization_spaces=False)
print(generated_code)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
# version 2
from transformers import AutoModelForCausalLM, AutoTokenizer
checkpoint = "replit_replit-code-v1-3b"
tokenizer = AutoTokenizer.from_pretrained(checkpoint, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(checkpoint, trust_remote_code=True)
model.cuda()
x = tokenizer.encode('### Instruction:\n\nwrite a bubble sort method in csharp, the argument is `int[]`\n\n### Response:\n', return_tensors='pt').to("cuda")
x = tokenizer.encode('def fibonacci(n): ', return_tensors='pt').to("cuda")
x = tokenizer.encode('using System.Collections;\nusing System.Collections.Generic;\nusing UnityEngine;\nusing NaughtyAttributes;\nusing UnityQuery;\n\npublic class CapturedEnergyBallTest : KXMonoBehaviour\n{\n public float destroyTime = 10f;\n\n public Transform startPosTarget;\n\n // Start is called before the first frame update\n void Start()\n {\n\n }\n\n // Update is called once per frame\n void Update()\n {\n \n }\n\n [Button]\n public void MakeOne(){\n var effectPrefab = BattleController.Instance.EffectPrefabMgr.capturedEnergyBallEffect;\n var effect = EffectPrefabMgr.InsCommonEffect(effectPrefab);\n effect.transform.position = startPosTarget.position;\n\n var capturedEnergyBall = effect.GetComponent<CapturedEnergyBall>();\n capturedEnergyBall.handTarget = this.CachedTransform;\n\n // destroy effect in 12s', return_tensors='pt').to("cuda")
y = model.generate(x, max_new_tokens=120, do_sample=True, top_p=0.95, top_k=4, temperature=0.2, num_return_sequences=1, eos_token_id=tokenizer.eos_token_id)
# decoding, clean_up_tokenization_spaces=False to ensure syntactical correctness
generated_code = tokenizer.decode(y[0], skip_special_tokens=True, clean_up_tokenization_spaces=False)
print(generated_code)
|
- unity 的后续代码补全还行
- 但是这个不支持 instruction
优先考虑 teknium_Replit-v2-CodeInstruct-3B , 虽然这个生成出来的东西总是多很多, 但是这个支持 instrcution 去写一些内容。
结论
下面时间内容都基于笔者的丐版3060 12G。
fauxpilot 的速度最快, 行间补全的话, 速度是一个很重要的内容。
- 快的话200 ~ 300 毫秒可以生成一个回答
- 慢的话, 大约1200 毫秒左右。
- 提交的内容越多, 速度越慢。
codellama
- 笔者写了一个测试脚本进行测试。 连续发送6次请求
- 6次中的第一次的时间大多都是 2600ms
- 6次中的后续几次基本都是 1500ms
- 但是这6次的请求的内容都是一致的。 可能对性能会有一些影响。
- 重复了几轮, 大概都是相同的结果。
- 虽然行间补全速度太慢, 但是生成大块代码的话, 还好。
- 不过, 大块代码的问题是 可能会给出错误的答案。
笔者想找一个既能支持行间补全, 又能聊天的模型, 但是没有找到。
现在的方案是 fauxpilot + openai API 来实现的。。
